Basics > Proportions > Single proportion
Compare a single proportion to the population proportion
The single proportion (or one-sample) binomial test is used to
compare a proportion of responses or values in a sample of data to a
(hypothesized) proportion in the population from which our sample data
are drawn. This is important because we seldom have access to data for
an entire population. The hypothesized value in the population is
specified in the Comparison value box.
We can perform either a one-sided test (i.e., less than
or greater than) or a two-sided test (see the
Alternative hypothesis dropdown). We use one-sided tests to
evaluate if the available data provide evidence that a sample proportion
is larger (or smaller) than the comparison value (i.e., the population
value in the null-hypothesis).
Example
A car manufacturer conducted a study by randomly sampling and interviewing 1,000 consumers in a new target market. The goal of the study was to determine if consumers would consider purchasing this brand of car.
Management has already determined that the company will enter this segment. However, if brand preference is lower than 10% additional resources will be committed to advertising and sponsorship in an effort to enhance brand awareness among the target consumers. In the sample, 93 consumers exhibited what the company considered strong brand liking.
You can find information on the responses by survey participants in
the consider.rda data set. The data set contains two
variables, id and consider.
Our null-hypothesis is that the proportion of consumers that would
consider the car brand for a future purchase is equal to 10%. Select the
consider variable from the Variable dropdown.
To evaluate the proportion of yes responses in the sample
select yes from the Choose level dropdown.
Choose the Less than option from the
Alternative hypothesis drop-down to determine if the
available data provides sufficient evidence to reject the
null-hypothesis in favor of the alternative that the proportion of
consumers that will consider the brand is less than
10%.
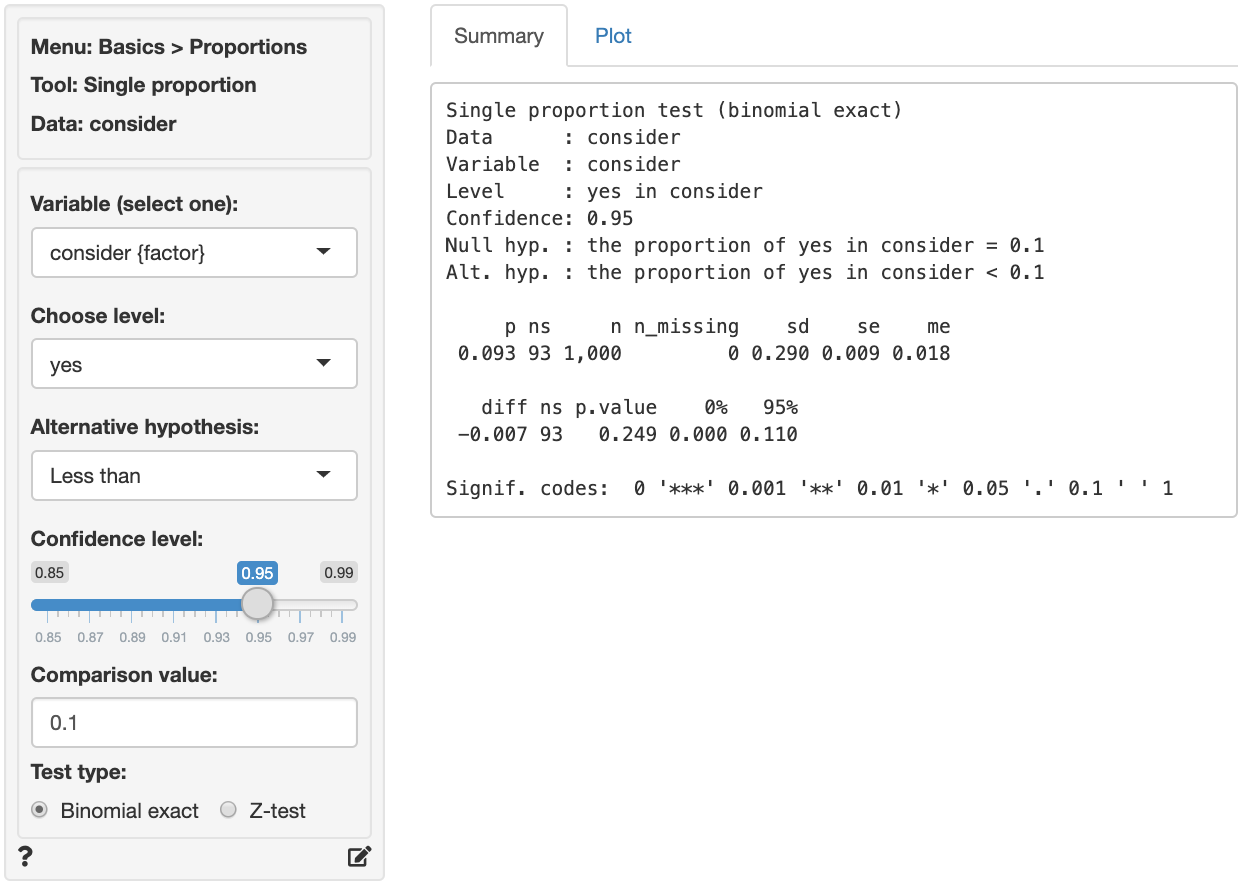
The first two blocks of output show basic information about the test (e.g.,. the null and alternative hypothesis) and summary statistics (e.g., the proportion of “yes” responses, standard error, margin or error, etc.). The final row of output shows the following:
diffis the difference between the sample proportion (0.093) and the comparison value (0.1)nsis the number of successes. This is the number we can compare to a binomial-distribution with parameters \(n = 1000\) and \(p = 0.10\).p.valueis the probability of finding a value as extreme or more extreme thandiffif the null hypothesis is true0% 95%show the 95% confidence interval around the sample proportion (0 to 0.11). These numbers provide a range within which the true population mean is likely to fall
Testing
There are three approaches we can use to evaluate the null hypothesis. We will choose a significance level of 0.05.1 Of course, each approach will lead to the same conclusion.
p.value
Because the p.value is larger than the conventional significance level (\(0.249 > 0.05\)) we cannot reject the null hypothesis and do not suggest that management should commit resources to increase brand awareness.
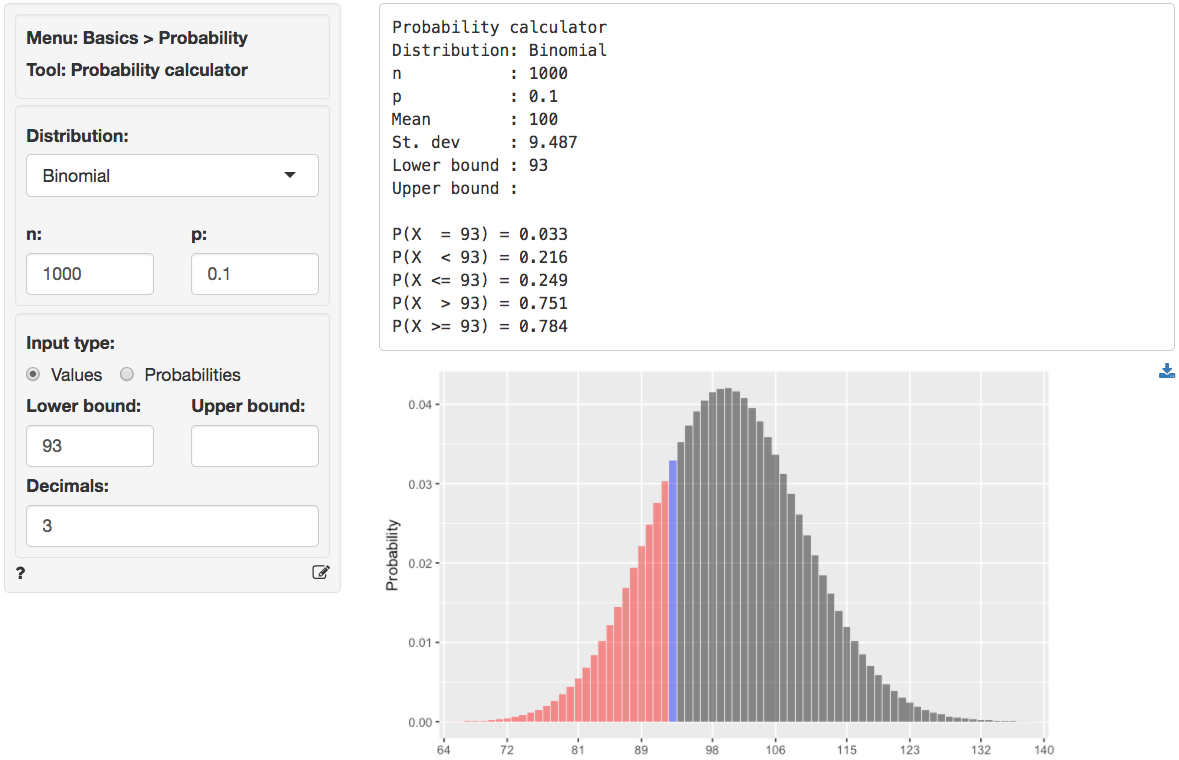
We can also obtain the p.value by using the probability calculator in the Basics menu. Enter the number of successes in the data (93) as the lower bound (value) for a binomial-distribution with \(n = 1000\) and \(p = 0.1\). The p.value is the probability of observing a number of successes as or more extreme than the 93 we got in our sample. We see that \(P(X <= 93) = 0.249\) which is the same value we got from Basics > Proportions > Single proportion.
confidence interval
Because the comparison value is
contained in the confidence interval (i.e., \(0 < 0.1 < 0.11\)) we
cannot reject the null hypothesis and do not
suggest that management should commit resources to increase
brand awareness.
number of successes
We can obtain the critical value by using the probability calculator
in the Basics menu. For a binomial-distribution with \(n = 1000\) and \(p = 0.1\) the critical value is 85. We have
to enter 0.05 as the lower probability bound because the alternative
hypothesis is Less than.2
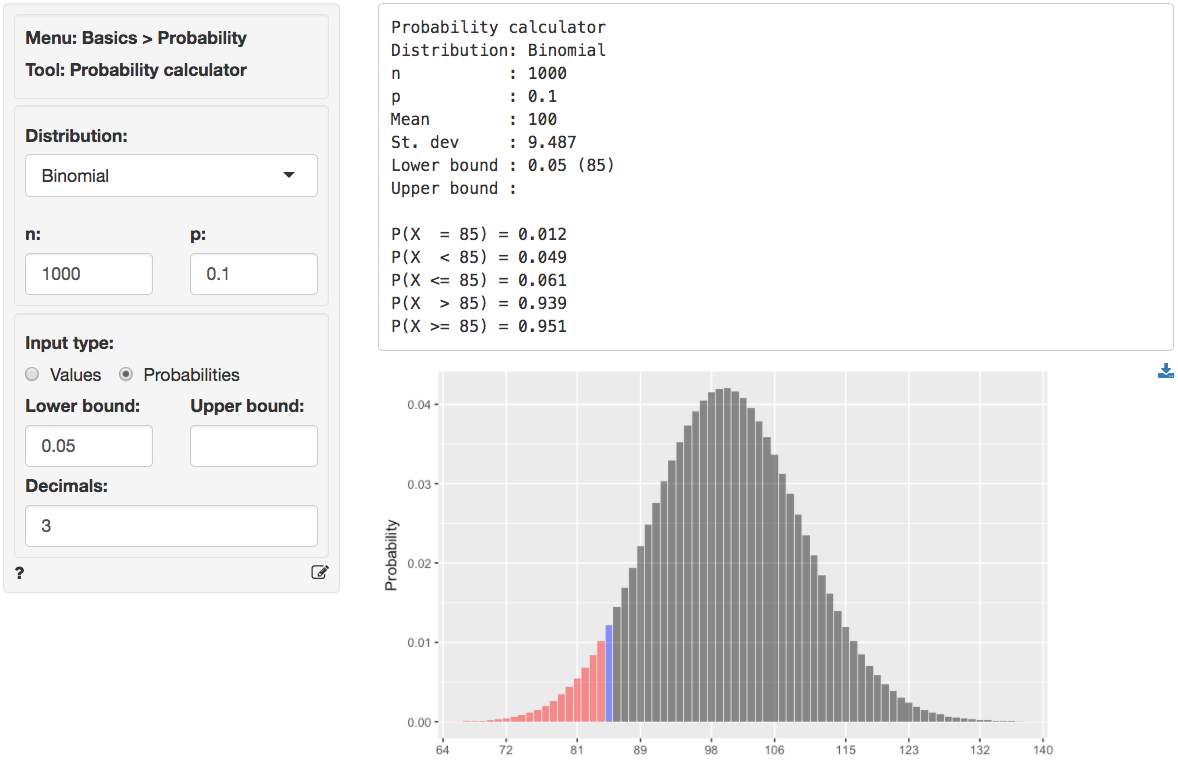
Because the number of successes (i.e., the number of “yes” responses) is larger than the critical value (93 vs 85) we cannot reject the null hypothesis and do not suggest that management should commit resources to increase brand awareness.
Stats speak
This is a single proportion test of the null hypothesis that the true population proportion is equal to 0.1. Using a significance level of 0.05, we cannot reject the null hypothesis, and cannot conclude that the true population proportion is less than 0.1.
The p.value for this test is 0.249. This is the probability of observing a sample proportion (or number of successes) that is as or more extreme than the sample value we estimated from the data if the null hypothesis is true. In this case, it is the probability of observing a sample proportion (number of successes) that is less than (or equal to) 0.093 (93) if the true population proportion is 0.1.
The 95% confidence bound is 0.11. If repeated samples were taken and the 95% confidence bound computed for each one, the true population proportion would be below that bound in 95% of the samples
1 The significance level, often denoted by \(\alpha\), is the highest probability you are willing to accept of rejecting the null hypothesis when it is actually true. A commonly used significance level is 0.05 (or 5%)
2 \(1 - \alpha\) is called the confidence level. A commonly used confidence level is 0.95 (or 95%)
Report > Rmd
Add code to
Report
> Rmd to (re)create the analysis by clicking the
icon on the bottom
left of your screen or by pressing ALT-enter on your
keyboard.
If a plot was created it can be customized using ggplot2
commands (e.g.,
plot(result, plots = "bar", custom = TRUE) + labs(y = "Percentage")).
See
Data
> Visualize for details.
R-functions
For an overview of related R-functions used by Radiant to evaluate proportions see Basics > Proportions.
The key functions from the stats package used in the
single_prop tool are binom.test and
prop.test.
Video Tutorials
Copy-and-paste the full command below into the RStudio console (i.e., the bottom-left window) and press return to gain access to all materials used in the hypothesis testing module of the Radiant Tutorial Series:
usethis::use_course("https://www.dropbox.com/sh/0xvhyolgcvox685/AADSppNSIocrJS-BqZXhD1Kna?dl=1")
Single Proportion Hypothesis Test
- This video shows how to test a hypothesis about a single sample proportion versus a population proportion
- Topics List:
- Setup a hypothesis test for a single proportion in Radiant
- Use the p.value, confidence interval, or critical value to evaluate the hypothesis test